
在上篇文章《HBase简介》中,已经提到过,HBase中的Table中的所有行都按照row key的字典序排列,Table 在行的方向上分割为多个Hregion:
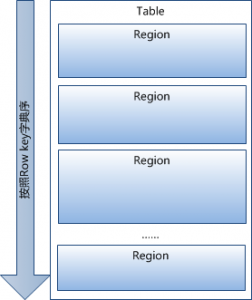
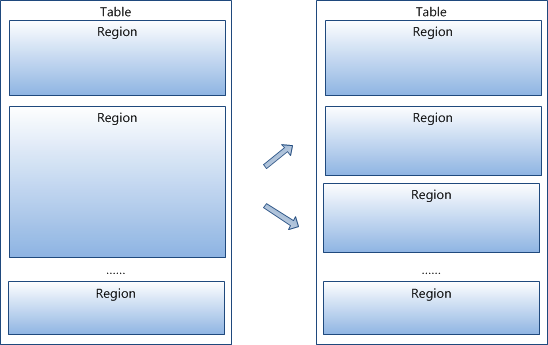
region按大小分割的,每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion。当table中的行不断增多,就会有越来越多的Hregion。
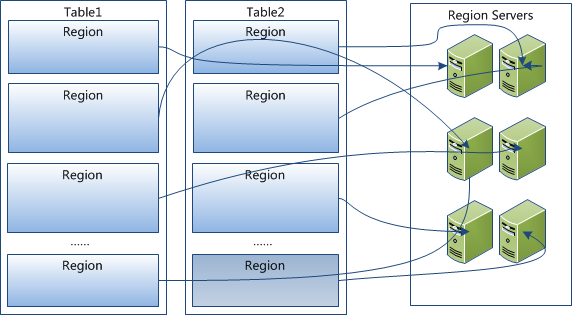
HRegion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的。
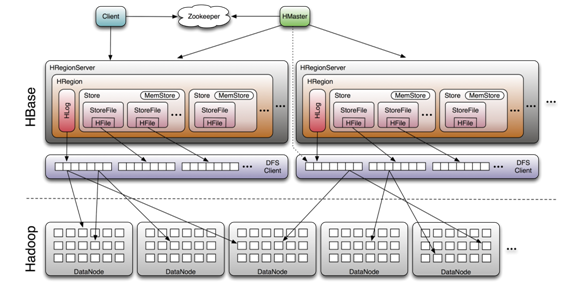
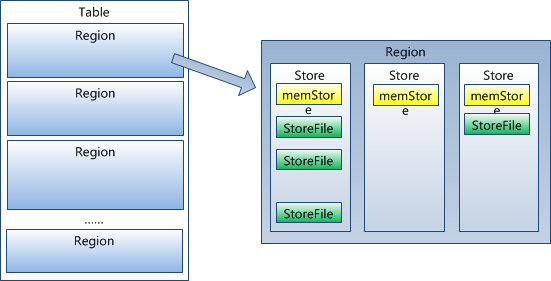
HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。事实上,HRegion由一个或者多个Store组成,每个store保存一个columns family。每个Strore又由一个memStore和0至多个StoreFile组成。StoreFile以HFile格式保存在HDFS上。如图:
HFile的格式为:
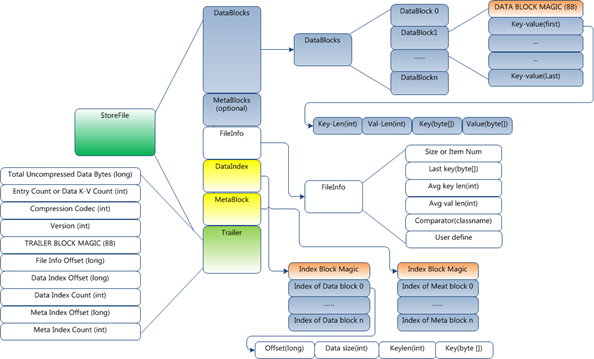
HFile分为六个部分:
Data Block 段–保存表中的数据,这部分可以被压缩
Meta Block 段 (可选的)–保存用户自定义的kv对,可以被压缩。
File Info 段–Hfile的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
Data Block Index 段–Data Block的索引。每条索引的key是被索引的block的第一条记录的key。
Meta Block Index段 (可选的)–Meta Block的索引。
Trailer– 这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。
目标Hfile的压缩支持两种方式:Gzip,Lzo。
系统架构
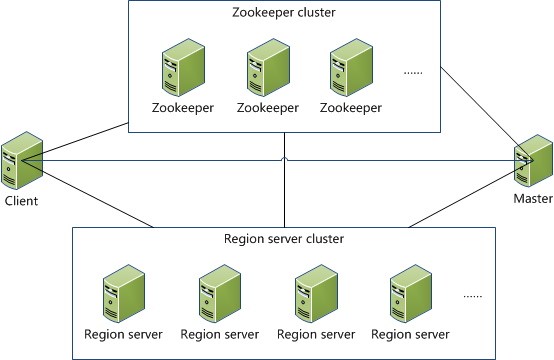
Client
1. 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如regione的位置信息。
Zookeeper
1. 保证任何时候,集群中只有一个master
2. 存贮所有Region的寻址入口。
3. 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4. 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Master
1. 为Region server分配region
2. 负责region server的负载均衡
3. 发现失效的region server并重新分配其上的region
4. GFS上的垃圾文件回收
5. 处理schema更新请求
Region Server
1.Region server维护Master分配给它的region,处理对这些region的IO请求
2.Region server负责切分在运行过程中变得过大的region
可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。

Comments