
本文将介绍C语言程序怎样通过模块化地组织成有结构的.
本文地址:http://wuyudong.com/2016/12/04/3132.html,转载请注明出处。
什么是模块化
模块化是将大型程序通过小的部分组织在一起,例如:模块,每一个模块对客户模块都有良好的接口定义,来指定怎样有效地使用这些接口所提供的服务,每一个模块的实现部分的代码都被隐藏,还有客户模块不关心的其他任何私有模块。
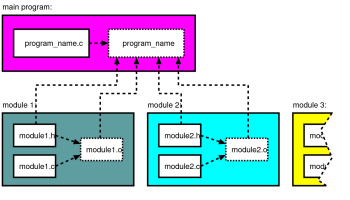
三个源文件的布局图,点框内的文件由编译器产生, 箭头表明文件被包含
模块化有一些好处,特别在大型复杂的程序:
- 模块可以在好几个项目里复用;
- 修改模块的实现细节不需要修改客户直到接口没有改变;
- 更快的复编译,因为只有被修改的模块实际上被复编译;
- 自文档,接口指定所有我们需要知道关于如何使用该模块;
- 更简单的调试,模块依赖性清晰地指定并且每个模块可以单独测试;
- 现代 C 编译器可以产生更快更短的可执行程序,它们可以释放整理私有变量和函数,有时候删除它们.
使用 C 语言编程的模块意味着将每个源代码拆分成头文件 module1.h 和一个对应的代码文件 module1.c h 。头文件仅仅包含常量的声明,类型,全局变量和函数原型,这些客户程序被允许访问和使用。每一个其他模块中私有的内部条目必须留在源代码文件中,我们接下来详细描述头文件和代码文件.
头文件
每一个头文件都应该以一个关于目的,目标,作者,版权信息,版本等简单的描述开始,所有的这些信息都是简单的C 注释。下面是我们的头文件 module1.h 的基本结构:
/*
module1.h -- C模块例子的结构
Copyright 2016 by wuyudong
License: as you wish
Author: wuyudong <codingwu@gmail.com>
Version: 2016-12-03
Updates: www.wuyudong.com
*/
#ifndef _MODULE1_H_
#define _MODULE1_H_
/* 下面的声明必须包含的头文件: */
#include <stdlib.h>
#include <math.h>
#include "some_other.h"
/* 设置 EXTERN 宏: */
#ifdef MODULE1_IMPORT
#define EXTERN
#else
#define EXTERN extern
#endif
/* 此处常量声明. */
/* 此处类型声明. */
/* 此处全局变量声明. */
/* 此处函数原型. */
#undef MODULE1_IMPORT
#undef EXTERN
#endif
MODULE1_IMPORT 和 EXTERN 宏的意义将在下面的段落解释,致力于全局变量。如果客户端模块没有定义 MODULE1_IMPORT 宏,EXTERN 的值将代表关键字 extern。相反,我们将看到 MODULE1_IMPORT 宏通过我们的代码模块被定义 。
作为一般规则,为了在全局命名空间中防止冲突,每一个公共标志符必须使用模块的名字作为前缀,接着下划线,接着实际的名字。
头文件:常量声明
常量可以是简单的宏或者枚举类型值。 枚举更适合于定义一个新的类型并接着类型声明的讨论。 通常常量是简单的int 或 double 数字,但是 float 和字面字符串也是允许的.
/* module1.h -- 常量声明 */ #define MODULE1_MAX_BUF_LEN (4*1024) #define MODULE1_RED_MASK 0xff0000 #define MODULE1_GREEN_MASK 0x00ff00 #define MODULE1_BLUE_MASK 0x0000ff #define MODULE1_ERROR_FLAG (1<<0) #define MODULE1_WARNING_FLAG (1<<1) #define MODULE1_NOTICE_FLAG (1<<2) #define MODULE1_EARTH_RADIUS 6367.445 /* 米 */
头文件:类型声明
这部分的头文件包含枚举声明,数据结构声明和不透明的数据结构声明。枚举适合用来声明一些常量,结构体声明适合于其内部细节可以通过客户端模块来读取和写入。
不透明的数据结构是内部细节,对客户模块不可见,不透明的类型只在代码模块中声明,这样客户模块不能访问它们的内部细节。客户模块不能动态分配不透明的数据结构,也不能声明这些类型的数组,因为它们的大小只在它们的代码模块内部可见。因为客户模块只能处理指向不透明类型的指针,代码模块必须提供被要求的分配和初始化例程, 其典型的名字如下设计 module_type_alloc() 和 module_type_free() .
/* module1.h -- 类型定义 */
enum module1_direction {
MODULE1_NORTH,
MODULE1_EAST,
MODULE1_SOUTH,
MODULE1_WEST
};
typedef struct _module1_node
{
struct _module1_node *left, *right;
char * key;
} module1_node;
typedef struct _module1_opaque module1_opaque;
头文件:全局变量
根本上避免公共全局变量是一个好的规则。但是如果你真的需要它们,下面是处理它们声明和初始化的有效方法。宏被要求来分配代码模块的文本区变量。如果没有这个宏,每一个客户模块分配自己变量的拷贝,这不是我们希望的.
/* module1.h -- 声明全局变量 */
EXTERN int module1_counter
#ifdef MODULE1_IMPORT
= -1
#endif
;
EXTERN module1_node *module1_root
#ifdef MODULE1_IMPORT
= NULL
#endif
;
头文件:函数原型
所有的函数的声明需要从客户模块易访问,注意无参的函数需要使用void类型参数.
/* module1.h -- 函数原型 */ EXTERN void module1_init(void); /* 初始化这个模块. */ EXTERN void module1_free(void); /* 释放额外的数据结构. */ EXTERN module1_node * module1_add(char * key); /* 向三个根增加一个结点,返回分配的结点. */ EXTERN module1_opaque * module1_opaque_alloc(void); EXTERN void module1_opaque_free(module1_opaque * p); /* Memory handling of the opaque data type. */
代码文件
代码模块 module1.c 应该包含必须的头文件,,接着它应该在它自己的头文件前定义 MODULE1_IMPORT 宏, 包含它自己的头文件,编译器获取所有它需要的常量、类型和变量,更进一步,包含它自己的头文件,代码文件分配和初始化头文件中的全局变量。包含头文件的另一个用途是对实际的函数进行原型检查,比如你忘记一些原型里面的参数,或者改变了代码而忘记更新头文件,于是编译器将会察觉到不匹配而提示错误信息.
代码文件中的宏、常量和类型声明不能对外访问,通常称为“私有的”。
内部的全局变量必须使用 static 关键字来使得他们是“私有的”。
通样记得声明所有的函数为 static 的,这样它们对代码模块而言是私有的。static 关键字告诉编译器这个函数不能用于链接,并且它们一经编译成目标文件 module1.o 将再也不可输出。
既然所有的私有的条目不可输出,没有必要预先考虑模块名 module1_ , 它们不能与外部项形成冲突。私有项仍然对调试有效.
/* module1.c */
#include <malloc.h>
#include <string.h>
/* 包含我们自己的头文件: */
#define MODULE1_IMPORT
#include "module1.h"
/* 私有宏和常量: */
/* 私有类型: */
/* 公有不透明的类型: */
typedef struct _module1_opaque
{
...
} _module1_opaque;
/* 私有的全局变量: */
static module1_node * spare_nodes = NULL;
static int allocated_total_size = 0;
/* 私有的函数: */
static module1_opaque * alloc_opaque(void){ ... }
static void free_opaque(module1_opaque * p){ ... }
/* 公有函数: */
void module1_init(void){ ... }
module1_node * module1_add(char * key){ ... }
void module1_free(void){ ... }
注意到公共函数放在最后,公共函数已经具备原型,可以被它们前面的所有地方调用.
主程序
我们项目的名字 program_name,它的源代码文件是 program_name.c,它仅仅包含公共函数和mian函数, 没有函数原型,主程序代码包含和初始化所有要求的模块,并且一旦程序结束就终止它们,主程序代码文件的通常结构如下:
/*
program_name.c -- 示例程序
Copyright 2016 by wuyudong
License: as you wish
Author: wuyudong <codingwu@gmail.com>
Version: 2016-12-03
Updates: www.wuyudong.com
*/
/* 包含标准头文件: */
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
/* 包含我们的模块头文件: */
#include "module1.h"
#include "module2.h"
#include "module3.h"
int main(int argc, char **argv)
{
/* 初始化模块: */
module1_init();
module2_init();
/* 运行我们的程序. */
/* 如果有必要恰当地结束模块: */
module2_free();
module1_free();
return 0;
}
Makefile
编译、链接和其他的普通典型的任务通常被委派给一个 Makefile,make 指令的配置文件,make 已经包含默认的规则告知怎样通过我们的源代码文件 file *.c 来建立目标文件 files *.o ,但是不幸的是它不会意识到源代码文件的模块化结构。为了处理模块,我们必须告诉 make 还有*.h 头文件必须添加到它的依赖性规则。这需要明确的规则而不是使用默认的依赖规则。更进一步,主程序必须使用其他的规则来编译同时指定一些外部的库来进行链接。最后显示一下Makefile 结构:
# Makefile
# Compiler flags: all warnings + debugger meta-data
CFLAGS = -Wall -g
# External libraries: only math in this example
LIBS = -lm
# Pre-defined macros for conditional compilation
DEFS = -DDEBUG_FLAG -DEXPERIMENTAL=0
# The final executable program file, i.e. name of our program
BIN = program_name
# Object files from which $BIN depends
OBJS = module1.o module2.o module3.o
# This default rule compiles the executable program
$(BIN): $(OBJS) $(BIN).c
$(CC) $(CFLAGS) $(DEFS) $(LIBS) $(OBJS) $(BIN).c -o $(BIN)
# This rule compiles each module into its object file
%.o: %.c %.h
$(CC) -c $(CFLAGS) $(DEFS) $< -o $@
clean:
rm -f *~ *.o $(BIN)
depend:
makedepend -Y -- $(CFLAGS) $(DEFS) -- *.c
通过这个 Makefile,编译源代码变得和运行 make 指令一样的简单,不需要参数,其他的标签同样要呈现,就像make clean, make dist 等。最后的标签make depend 接下来讲解.
依赖于其他模块的模块
直到现在我们认为三个源代码很简单,主程序依赖于一些独立的模块,如果任何的源代码文件修改 %.o 规则维护 *.o 文件的更新,如果它的源代码或者任何模块更新 $(BIN) 规则重编译和重链接主程序.
但是假如一些模块依赖于其他的子模块,既在头部包含它又在它的代码文件包含它怎么办?假如模块除了对主程序有贡献,还相互依赖该怎么办?下图解释了一种情况:模块 module1.h/.c 需要子模块 module4.h, module2 需要 module3.
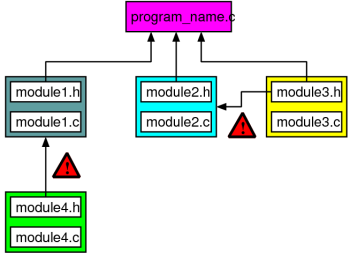
特殊的标记产生依赖可以帮助我们处理所有枯燥的工作,因为它能自动地编译所有源代码文件的依赖并将其添加到makefile本身:
---- The Makefile as above, but remember to add ---- ---- module4.o to the list of the object files. ---- # DO NOT DELETE module1.o: module4.h module2.o: module3.h program_name.o: module1.h module2.h module3.h module4.h
最后的建议
GNU GCC 编译器具有 -Wall 标志能显示所有可能的警告信息,我经常使用它因为它帮我写干净的代码,还拯救了很多难以察觉的模糊错误。
你可以使用 nm 命令来避开模块化从而检查一些内部的项 (变量或者函数) ,这个命令展示了指定目标文件中所有可获得的符号表,既对于连接器又对于调试器。对于每一个符号,这个命令还会打印一个字母来表示它的状态和可用性:
$ nm module1.o 00000000 t alloc_opaque 0000000c b allocated_total_size 00000014 T module1_add 00000000 D module1_counter 0000001e T module1_free 0000000f T module1_init 00000004 B module1_root 0000000a t free_opaque 00000008 b spare_nodes
简单的 grep 可以通过模块立刻检测变量和项的实际出口:
$ nm module1.o | grep " [A-Z] " 00000014 T module1_add 00000000 D module1_counter 0000001e T module1_free 0000000f T module1_init 00000000 B module1_root
我们可以完善这个shell 命令,写一个有用的工具来显示每一个模块所有错误的出口专用标识符:
#!/bin/sh
# Usage: c-detect-private-exported *.o
echo "Detecting private items exported by object files:"
while [ $# -gt 0 ]; do
base=`basename $1 .o`
nm $1 | grep " [A-Z] " | cut -d " " -f3 |
while read id; do
grep -q -w $id $base.h || echo " $id"
done
shift
done

Comments