
链接器和加载器做什么?
任何一个链接器和加载器的基本工作都非常简单: 将更抽象的名字与更底层的名字绑定起来,好让程序员使用更抽象的名字编写代码。也就是说,它可以将程序员写的一个诸如 getline 的名字绑定到“iosys 模块内可执行代码的 612 字节处”或者可以采用诸如“这个模块的静态数据开始的第 450 个字节处”这样更抽象的数字地址然后将其绑定到数字地址上。
本文地址:http://wuyudong.com/2016/08/21/2526.html,转载请注明源地址。
地址绑定:从历史的角度
最早的计算机完全是用机器语言进行编程的。程序员需要在纸质表格上写下符号化程 序,然后手工将其汇编为机器码,通过开关、纸带或卡片将其输入到计算机中(真正的高手可以在开关上直接编码)。如果程序员使用符号化的地址,那他就得手工完成符号到地址的 绑定。如果后来发现需要添加或删除一条指令,那么整个程序都必须手工检查一遍并将所有被添加或删除的指令影响的地址都进行修改。
这个问题就在于名字和地址绑定的过早了。汇编器通过让程序员使用符号化名字编写程序,然后由程序将名字绑定到机器地址的方法解决了这个问题。如果程序被改变了,那么程序员必须重新汇编它,但是地址分配的工作已经从程序员推给计算机了。代码的库使得地址分配工作更加复杂。由于计算机可以执行的基本操作极其简单,有用的程序都是由那些可以执行更高级、更复杂操作的子程序组成的。计算机在安装时都带有 一些预先编写好、调试好的子例程库,程序员可以将它们用在自己写的新程序中,而不需编 写所有的子程序。然后程序员可以将这些子例程加载到主程序中以构成一个完整的可以工作的程序。
随着操作系统的出现,有必要将可重定位的加载器从链接器和库中分离出来。在有操作系统之前,一个程序可以支配机器所有的内存,由于知道计算机中所有的地址都是可用的, 因此它能以固定的内存地址来汇编和链接。但是有了操作系统以后,程序就必须和操作系统甚至其它程序共享计算机的内存。这意味着在操作系统将程序加载到内存之前是无法确定程序运行的确切地址的,并将最终的地址绑定从链接时推延到了加载时。现在链接器和加载器已经将这个工作划分开了,链接器对每一个程序的部分地址进行绑定并分配相对地址,加载器完成最后的重定位步骤并赋予的实际地址
随着计算机系统变得越来愈复杂,链接器被用来做了更多、更复杂的名字管理和地址绑定的工作。Fortran 程序使用了多个子程序和公共块(被多个子程序共享的数据区域), 而它是由链接器来为这些子程序和公共数据块进行存储布局和地址分配的。逐渐地链接器还需要处理目标代码库。包括用 Fortran 或其它语言编写的应用程序库,并且编译器也支持那些可以从被编译好的处理 I/O 或其它高级操作的代码中隐含调用的库。
由于程序很快就变得比可用的内存大了,因此链接器提供了覆盖技术,它可以让程序员安排程序的不同部分来分享相同的内存,当程序的某一部分被其它部分调用时可以按需加载。上世纪 60 年代在硬盘出现后覆盖技术在大型主机系统上得到了广泛的应用,一直持续到 70 年代中期虚拟内存技术出现。然后重新以几乎相同的形式在 80 年代早期的微型机算机上出现,并在 90 年代 PC 上采用虚拟内存后逐渐没落。现在它们仍被应用在内存受限的嵌入式环境中,并且当程序员或者编译器为了提高性能而精确的控制内存使用时可能会再次出现。
随着硬件重定位和虚拟内存的出现,每一个程序可以再次拥有整个地址空间,因此链接器和加载器变得不那么复杂了。由于硬件(而不是软件)重定位可以对任何加载时重定位进行处理,程序可以按照被加载到固定地址的方式来链接。但是具有硬件重定位功能的计算机往往不止运行一个程序,而且经常会运行同一个程序的多个副本。当计算机运行一个程序的多个实例时,程序中的某些部分在所有的运行实例中都是相同的(尤其是可执行代码), 而另一些部分是各实例独有的。如果不变的部分可以从发生改变的部分中分离出来,那么操作系统就可以只使用一份不变部分的副本,节省相当可观的存储空间。编译器和汇编器可以 被修改为在多个段内创建目标代码,为只读代码分配一个段,为别的可写数据分配其它段。 链接器必须能够将相同类型的所有段都合并在一起,以使得被链接程序的所有代码都放置在一个地方,而所有的数据放在另一个地方。由于地址仍然是在链接时被分配的,因此和之前相比并不能延迟地址绑定的时机,但更多的工作被延迟到了链接器为所有段分配地址的时候。
即使多个不同的程序运行在一个计算机上时,这些不同的程序实际上仍会共享很多公共代码。例如,几乎每一个 C 语言的程序都会使用诸如 fopen 和 printf 这样的例程,数据库应用程序都会使用一个巨大的访问库来链接数据库,运行在诸如 X Window,MS Windows,或 Macintosh 这样的图形用户界面下的应用程序会使用到部分的图形用户界面库。多数系统现在都会提供共享库给应用程序使用,这样所有使用某个库的程序可以仅共享一份副本。这既提升了不少运行时的性能也节省了大量磁盘空间:在小程序中通用库例程会占用比主程序本身更多的空间。
在较简单的静态共享库中,每个库在创建时会被绑定到特定的地址,链接器在链接时将程序中引用的库例程绑定到这些特定的地址。由于当静态库中的任何部分变化时程序都需要被重新链接,而且创建静态链接库的细节也是非常冗长乏味的,因此静态链接库实际上很麻烦死板。故又出现了动态链接库,使用动态链接库的程序在开始运行之前不会将所用库中的段和符号绑定到确切的地址上。有时这种绑定还会更为延迟:在完全的动态链接中,被调 用例程的地址在第一次调用前都不会被绑定。此外在程序运行过程中也可以加载库并进行绑 定。这提供了一种强大且高性能的扩展程序功能的方法。尤其是微软 Windows 广泛的使用了运行时加载共享库(如我们所知的 DLL,Dynamiclly Linked Libraries)对程序进行构建和 扩展。
链接与加载
链接器和加载器完成几个相关但概念上不同的动作。
• 程序加载:将程序从辅助存储设备(自 1968 年后这就意味着磁盘)拷贝到主内存中准备运行。在某些情况下,加载仅仅是将数据从磁盘拷入内存;在其他情况下,还包括分配存储空间,设置保护位或通过虚拟内存将虚拟地址映射到磁盘内存页上。
• 重定位:编译器和汇编器通常为每个文件创建程序地址从 0 开始的目标代码,但是几乎没有计算机会允许从地址 0 加载你的程序。如果一个程序是由多个子程序组成 的,那么所有的子程序必须被加载到互不重叠的地址上。重定位就是为程序不同部分分配加载地址,调整程序中的数据和代码以反映所分配地址的过程。在很多系统中,重定位不止进行一次。对于链接器的一种普遍情景是由多个子程序来构建一个程序,并生成一个链接好的起始地址为 0 的输出程序,各个子程序通过重定位在大程序中确定位置。当这个程序被加载时,系统会选择一个加载地址,而链接好的程序会作为整体被重定位到加载地址。
• 符号解析:当通过多个子程序来构建一个程序时,子程序间的相互引用是通过符号进行的;主程序可能会调用一个名为 sqrt 的计算平方根例程,并且数学库中定义了 sqrt 例程。链接器通过标明分配给 sqrt 的地址在库中来解析这个符号,并通过修改目标代码使得 call 指令引用该地址。
尽管有相当一部分功能在链接器和加载器之间重叠,定义一个仅完成程序加载的程序为加载器,一个仅完成符号解析的程序为链接器是合理的。他们任何一个都可以进行重定位,而且曾经也出现过集三种功能为一体的链接加载器。
重定位和符号解析的划分界线是模糊的。由于链接器已经可以解析符号的引用,一种处理代码重定位的方法就是为程序的每一部分分配一个指向基址的符号,然后将重定位地址认为是对该基址符号的引用。
链接器和加载器共有的一个重要特性就是他们都会修改目标代码,他们也许是唯一比调试程序在这方面应用更为广泛的程序。这是一个独特而强大的特性,而且细节非常依赖于 机器的规格,如果做错的话就会引发令人困惑的bug
两遍链接
现在我们来看看链接器的普遍结构。就象编译或汇编一样,链接基本上也是一个两遍的过程。链接器将一系列的目标文件、库、及可能的命令文件作为它的输入,然后将输出的目标文件作为产品结果,此外也可能有诸如加载映射信息或调试器符号文件的副产品。图 1
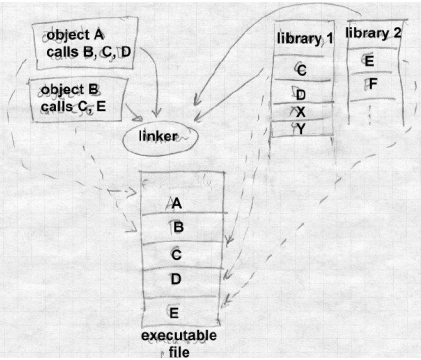
重定位和代码修改
链接器和加载器的核心动作是重定位和代码修改。当编译器或汇编器产生一个目标代码文件时,它使用文件中定义的未重定位代码地址和数据地址来生成代码,对于其它地方定义的数据或代码通常就是 0。作为链接过程的一部分,链接器会修改目标代码以反映实际分配的地址。例如,考虑如下这段将变量 a 中的内容通过寄存器 eax 移动到变量 b 的 x86 代码片段。
mov a,%eax mov %eax,b
如果 a 定义在同一文件的位置 0x1234,而 b 是从其它地方导入的,那么生成的代码将会是:
A1 34 12 00 00 mov a,%eax A3 00 00 00 00 mov %eax b
每条指令包含了一个字节的操作码和其后 4 个字节的地址。第一个指令有对地址 1234 的引用(由于 x86 使用从右向左的字节序,因此这里是逆序),而第二个指令由于 b 的位置是未知的因此引用位置为 0。
现在想象链接器将这段代码进行链接,a 所属段被重定位到了0x10000,b 最终位于地 址0x9A12。则链接器会将代码修改为:
A1 34 12 01 00 mov a,%eax A3 12 9A 00 00 mov %eax,b
也就是说,链接器将第一条指令中的地址加上 0x10000,现在它所标识的 a 的重定位地 址就是 0x11234,并且也补上了 b 的地址。虽然这些调整影响的是指令,但是目标文件中数据部分任何相关的指针也必须修改。
在稍老一些的地址空间很小、直接寻址的计算机系统上,由于只有一到两种链接器需要处理的地址格式,因此代码修改的过程相当简单。对于现代计算机,包括所有的 RISC 架构,都需要进行复杂的多的代码修改。没有一条指令有足够的空间容纳一个直接地址,因此编译器和链接器不得不用复杂的寻址技巧来处理任意地址上的数据。某些情况下,使用两到三条指令来组成一个地址都是有可能的,每个指令包含地址的一部分,然后使用位操作将它们组合为一个完整的地址。在这种情况下,链接器不得不对每个指令都进行恰当的修改,将地址中的某些位插入到每一个指令中。其它情况下,一个例程或一组例程使用的所有地址都被放置在一个作为“地址池”的数组中,初始化代码将某一个机器寄存器指向这个数组,当需要时,代码会将该寄存器作为基址寄存器从地址池中加载所需指针。链接器需要由被程 序使用的所有地址来创建这个数组,并修改各指令使它们可以关联到正确的地址池入口处。 我们将在后面再讨论这些问题。
有些系统需要无论加载到什么位置都可以正常工作的位置无关代码。链接器需要提供 额外的技巧来支持位置无关代码,与程序中无法做到位置无关的部分隔离开来,并设法使这 两部分可以互相通讯(详见第 8 章)。
编译器驱动
很多情况下,链接器所进行的操作对程序员是几乎或完全不可见的,因为它会做为编译过程的一部分自动进行。多数编译系统都有一个可以按需自动执行编译器各个阶段的编译器驱动。例如,若一个程序员有两个 C 源程序文件(简称 A,B),那么在 UNIX 系统上编译器驱动将会运行如下一系列的程序:
C 语言预处理器处理 A,生成预处理的 A
C 语言编译预处理的 A,生成汇编文件 A
汇编器处理汇编文件 A,生成目标文件 A
C 语言预处理器处理 B,生成预处理的 B
C 语言编译预处理的 B,生成汇编文件 B
汇编器处理汇编文件 B,生成目标文件 B
链接器将目标文件 A、B 和系统 C 库链接在一起,也就是说,编译器驱动首先会将每个源文件编译为汇编语言,然后转换为目标代码,接着链接器会将目标代码链接器一起,并包含任何需要的系统 C 库例程。
编译器驱动通常要比这聪明的多,他们会比较源文件和目标代码文件的时间,仅编译那些被修改过的源文件(UNIX make 程序就是典型的例子)。尤其是在编译 C++和其它面向对象语言时,编译器驱动会使用各种各样的技巧来克服链接器或目标代码格式的局限。例如, C++模板定义了一个数量可能不限的相关例程的集合,这样就可以找到程序实际使用的数目有限的模板例程集合,编译器驱动可以在没有模板代码时将程序的目标文件链接在一起,然后读取链接器的错误信息查看未定义东西,再调用 C++编译器为需要的模板例程生成目标代码并再次链接。我们将在后面再讨论这些问题。
链接器命令语言
每个链接器都有某种形式的命令语言来控制链接过程。最起码链接器需要记录所链接的目标代码和库的列表。通常都会有一大长串可能的选项:在哪里放置调试符号,在哪里使用共享或非共享库,使用哪些可能的输出格式等。多数链接器都允许某些方法来指定被链接代码将要绑定的地址,这在链接一个系统内核或其它没有操作系统控制的程序时就会用到。在支持多个代码和数据段的链接器中,链接器命令语言可以对链接各个段的顺序、需要特殊处理的段和某些应用程序相关的选项进行指定。 有四种常见技术向链接器传送指令:
1、命令行: 多数系统都会有命令行(或相似功能的其它程序),通过它可以输入各种文件名和开关选项。这对于 UNIX 和 Windows 链接器是很常用的方法。对于那些命令行长度有限制的系统,常用的办法是让链接器从文件中读取命令并在命令行上那样对待他们。
2、与目标文件混在一起: 有些链接器,如 IBM 主机系统的链接器,从一个单个输入文件中接受替换的目标文件及链接器命令。这种方式来源于卡片输入的年代,那时程序员需要把目标代码卡片摞起来和手工打制的命令卡片一起送到读卡器中。
3、嵌入在目标文件中: 有一些目标代码格式,特别是微软的,允许将链接器命令嵌入 到目标文件中。这就允许编译器将链接一个目标文件时所需要的任何选项通过文件自身来传递。例如 C 编译器将搜索标准 C 库的命令嵌入到文件中(来传递给链接过 程)。
4、单独的配置语言: 极少有链接器拥有完备的配置语言来控制链接过程。可以处理众多目标文件类型、机器体系架构和地址空间规定的GNU 链接器,拥有可以让程序员指定段链接顺序、合并相近段规则、段地址和大量其它选项的一套复杂的控制语言。 其它链接器一般拥有诸如支持程序员可定义的重叠技术等特性的稍简单一些的配置语言。
链接:一个真实的例子
我们通过一个简小的链接实例来结束对链接过程的介绍。为一对 C 语言源代码文件m.c 中的主程序调用了一个名为 a 的例程,而调用了库例程 strlen 和 write 的 a 例程
源程序m.c:
extern void a(char *);
int main(int ac, char **av)
{
static char string[] = "Hello, world!\n";
a(string);
}
源程序a.c:
#include <unistd.h>
#include <string.h>
void a(char *s)
{
write(1, s, strlen(s));
}
将主程序m.c使用gcc编译成一个典型的a.out目标代码格式长度为984字节的目标文件。
使用命令:objdump -x m.o和objdump -S m.o查看得到如下信息:
Sections: Idx Name Size VMA LMA File off Algn 0 .text 00000017 00000000 00000000 00000034 2**0 CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE 1 .data 0000000e 00000000 00000000 0000004b 2**0 CONTENTS, ALLOC, LOAD, DATA 2 .bss 00000000 00000000 00000000 00000059 2**0 ALLOC Disassembly of section .text: 00000000 <main>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 83 e4 f0 and $0xfffffff0,%esp 6: 83 ec 10 sub $0x10,%esp 9: c7 04 24 00 00 00 00 movl $0x0,(%esp) 10: e8 fc ff ff ff call 11 <main+0x11> 15: c9 leave 16: c3 ret
LMA = load memory address
VMA = vitual memory address
该目标文件包含一个固定长度的头部,23个字节的“文本 ”段,包含只读的程序代码,14个字节的数据段,包含字符串。其后是两个重定位项,其中一个标明 push指令将字符串 string 的地址放置在栈上为调用例程 a 作准备,另一个标明 call 指令将控制转移到例程 a。符号表分别导出和导入了main 与a 的定义,以及调试器需要的其它一系列符号。 注意由于和字符串 string 在同一个文件中,push指令引用了 string 的临时地址 0x10,而由于_a 的地址是未知的所以 call 指令引用的地址为0x
子程序文件 a.c 编译成一个长度为 160 字节的目标文件,包括头部, 28 字节的文本段,无数据段。两个重定位项标记了对 strlen 和 write 的 call 指令,符号表中导出_a 并导入了_strlen 和_write。
a.c 的目标代码:
Sections: Idx Name Size VMA LMA File off Algn 0 .text 0000002a 00000000 00000000 00000034 2**0 CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE 1 .data 00000000 00000000 00000000 0000005e 2**0 CONTENTS, ALLOC, LOAD, DATA 2 .bss 00000000 00000000 00000000 0000005e 2**0 ALLOC Disassembly of section .text: 00000000 <a>: 0: 55 push %ebp 1: 89 e5 mov %esp,%ebp 3: 83 ec 18 sub $0x18,%esp 6: 8b 45 08 mov 0x8(%ebp),%eax 9: 89 04 24 mov %eax,(%esp) c: e8 fc ff ff ff call d <a+0xd> 11: 89 44 24 08 mov %eax,0x8(%esp) 15: 8b 45 08 mov 0x8(%ebp),%eax 18: 89 44 24 04 mov %eax,0x4(%esp) 1c: c7 04 24 01 00 00 00 movl $0x1,(%esp) 23: e8 fc ff ff ff call 24 <a+0x24> 28: c9 leave 29: c3 ret
为了产生一个可执行程序,链接器将这两个目标文件,以及一个标准的 C 程序启动初始化例程,和必要的 C 库例程整合到一起,产生一个部分如下所示的可执行文件
gcc -o main.o m.o a.o
可执行程序的部分代码
Sections: Idx Name Size VMA LMA File off Algn …… 12 .text 000001b2 08048350 08048350 00000350 2**4 CONTENTS, ALLOC, LOAD, READONLY, CODE …… 23 .data 00000016 0804a01c 0804a01c 0000101c 2**2 CONTENTS, ALLOC, LOAD, DATA 24 .bss 00000002 0804a032 0804a032 00001032 2**0 ALLOC Disassembly of section .text: 08048350 <_start>: …… 8048367: 68 4d 84 04 08 push $0x804844d 804836c: e8 bf ff ff ff call 8048330 <__libc_start_main@plt> …… 0804844d <main>: 804844d: 55 push %ebp 804844e: 89 e5 mov %esp,%ebp 8048450: 83 e4 f0 and $0xfffffff0,%esp 8048453: 83 ec 10 sub $0x10,%esp 8048456: c7 04 24 24 a0 04 08 movl $0x804a024,(%esp) 804845d: e8 02 00 00 00 call 8048464 <a> …… 08048464 <a>: 8048464: 55 push %ebp 8048465: 89 e5 mov %esp,%ebp 8048467: 83 ec 18 sub $0x18,%esp 804846a: 8b 45 08 mov 0x8(%ebp),%eax 804846d: 89 04 24 mov %eax,(%esp) 8048470: e8 ab fe ff ff call 8048320 <strlen@plt> 8048475: 89 44 24 08 mov %eax,0x8(%esp) 8048479: 8b 45 08 mov 0x8(%ebp),%eax 804847c: 89 44 24 04 mov %eax,0x4(%esp) 8048480: c7 04 24 01 00 00 00 movl $0x1,(%esp) 8048487: e8 b4 fe ff ff call 8048340 <write@plt> 804848c: c9 leave 804848d: c3 ret 804848e: 66 90 xchg %ax,%ax 08048320 <strlen@plt>: 8048320: ff 25 10 a0 04 08 jmp *0x804a010 8048326: 68 08 00 00 00 push $0x8 804832b: e9 d0 ff ff ff jmp 8048300 <_init+0x2c> 08048340 <write@plt>: 8048340: ff 25 18 a0 04 08 jmp *0x804a018 8048346: 68 18 00 00 00 push $0x18 804834b: e9 b0 ff ff ff jmp 8048300 <_init+0x2c>
链接器将每个输入文件中相应的段合并在一起,故只存在一个合并后的文本段,一个合并后的数据段和一个 bss 段(两个输入文件不会使用的,被初始化为 0 的数据段)。由于每个段都会被填充为4K对齐以满足 x86 的页尺寸,因此文本段为 4K(减去文件中 20 字节长 度的 a.out 头部,逻辑上它并不属于该段),数据段和 bss 段每个同样也是 4K 字节。
合并后的文本段包含名为 _start 的库启动代码,由 m.o 重定位到 8048330的代码,重定位到 8048464的 a.o,以及被重定位到文本段更高地址从 C 库中链接来的例程。数据段,没有显示在这里,按照和文本段相同的顺序包含了合并后的数据段。由于main 的代码被重定位到地址 804844d,所以这个代码要被修改到 _start代码的 call 指令中。在 main 例程内部,对字符串 string 的引用被重定位到804a024,,这是 string 在数据段最终的位置,并且 call 指令中地址修改为 8048464,这是a 最终确定的地址。在a 内部,对strlen 和write 的 cal l 指令也要修改为这两个例程的最终地址。
可执行程序中仍然有很多其它的 C 库例程,没有显示在这里,它们由启动代码和write直接或间接的调用。由于可执行程序的文件格式不是可以重链接的,且操作系统从已知的固定位置加载它,因此它不包含重定位数据。它带有一个有助于调试器(debugger)工作的符号表,尽管这个程序没有使用这个符号表并且可以将其删除。

Comments