
在写第一个malloc之前,我们需要理解在多任务系统中内存是怎样管理的。我们将保持一个抽象观点的视角来看,因为有很多细节关于系统和硬件依赖
1、进程的内存
每一个进程都有自己的虚拟地址空间,通过MMU(和内核)动态地转换成物理内存地址空间,这个空间分成几部分,我们需要了解的是哪些空间来存储代码,一个栈来存储本地与变量, 一些空间用于常量和全局变量,一个未组织的空间用于被称为堆的程序数据。 堆是连续空间的内存拥有三个边界:一个起始指针,一个最大值限制 (通过sys/ressource.h 里的函数 getrlimit(2) 和setrlimit(2)管理) 和一个名叫 break 的尾指针。 break标志映射内存空间的结尾,也即是这部分的虚拟地址空间已经对应物理内存, 图1 描述内存组织.
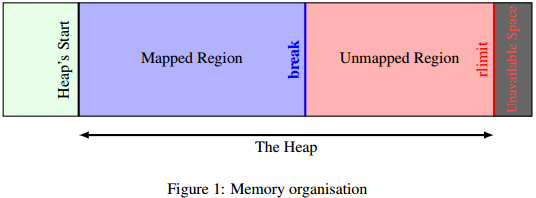
为了编写malloc, 我们需要知道heap的开始和break的位置,当然我们要能移动break的位置。这就是两个系统调用 brk 和 sbrk的目的。
本文地址:http://wuyudong.com/2016/07/26/2326.html,转载请注明源地址。
2、brk(2) and sbrk(2)
我们可以在手册中找到这些调用的描述
int brk(const void *addr); void* sbrk(intptr_t incr);
brk(2) 通过给定的addr参数定位到break的地址,如果成功的话返回0 否则返回 -1。 全局的错误(errno)标记表示错误的类型。
sbrk(2) 通过给定的增量(字节)来移动break。依赖于系统的实现,它返回以前或新的break地址。失败返回 (void *)-1 并设置errno。
在一些系统上sbrk 接收负数 (用来释放一些内存映射) 。由于sbrk的规范对于返回的结果的意义不统一,我们不会使用移动break的返回值。但是我们可以使用sbrk的一种特殊情形:当增量为nul(即sbrk(0)),返回值是实际的break地址(以前的和新的break地址是相同的)。结果sbrk被用来检索堆在break初始化的位置, 我们将使用 sbrk 作为我们实现malloc的主要工具。 我们所要做的就是获得更多的空间(如果需要的话)来完成查询
3、Unmapped Region (未映射区域)与No-Man’s Land(无人区)
通过前面了解到break 标记映射虚拟地址空间的结尾:访问break外的高位地址将触发一个总线错误。 break到堆的最大限制之间的空间,没有通过系统的虚拟内存管理(MMU 与内核的专用部分)来关联物理内存。但是如果你了解一点虚拟内存,你就会知道内存通过页映射:物理内存和虚拟内存在页里被组织 (物理内存是帧) 成固定大小 (多数情况下) 。页的大小远比一个字节大 (在实际系统中一个页的大小为 4096字节) ,结果break 不可能在页的边界。

图2 展示了前面提到的内存组织与页面边界。我们可以看到,break可能不对应于一个页面的边界。在break和下个页的边界之间的内存处于一个什么地位?事实上,这个区域是无效的,你可以访问这个区域的字节(例如读或写),问题是,你没有关于下一个边界位置的任何线索,你可以找到它,但它依赖系统和不被建议。
这块无人区往往是错误的根源:对于堆外部的一些错误的指针操作附加一些小规模的测试,大多数情况下都可以成功,但是仅当数据量大的操作的时候就会失败。
4、mmap(2)
即使在这个系列的教程里我们不使用,你都需要注意到系统调用mmap(2), 它具有一个匿名模式(mmap(2) is 通常用来在内存中直接映射文件)可以用来实现malloc(完全或部分的具体情况)。mmap在匿名模式下可以分配相当数量的内存 (page大小以上) 并且 munmap 可以释放它.。通常它更加简单,并比传统的基于sbrk的malloc更加高效 。 很多malloc 的实现使用 mmap 来进行垃圾回收。OpenBSD的 malloc 仅仅使用mmap的一些怪癖来提高安全性。

Comments