
hbase是一种搭建在hadoop上的数据库,理论上hbase可以搭建在任何分布式文件系统,只不过与hadoop的集成更加紧密,HDFS天生是一种可扩展的存储,但是还不足以支持hbase成为一种低延时的数据库
切分和分配大表
hbase中的表可能达到数十亿行和数百万列,每个表的大小可能达到TB级别,有时甚至PB级别,显然不可能在一台机器是存放整个表,于是表会切分成一个个叫做region的数据单位,托管region的服务器叫RegionServer
RegionServer和HDFS DataNode典型情况下配置在同一物理硬件上,但这不是必需的,唯一的要求是RegionServer能够访问HDFS客户端,主(master)进程分配region给RegionServer,每个RegionServer一般托管多个region。
单个region大小由hbase-site.xml文件里面的配置参数HBase.hregion.max.filesize决定
如何找到region
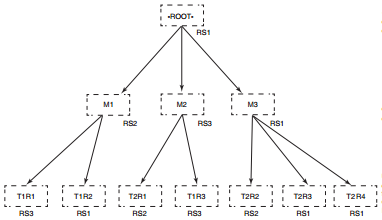
hbase中有两个特殊的表,-ROOT-和.META.,用来查找各种表的region位置在哪里。-ROOT-和.META.像hbase中其他表一样也会切分成region,-ROOT-和.META.都是特殊的表,但是-Root-更加特殊,它永远不会切分超过一个region,.META.和其他表一样可以按需要切分成许多region
当客户端要访问某一行时,先找-ROOT-表,找到什么地方可以找到负责某行的region。-ROOT-指向 .META.表的region,.META.由入口地址组成,客户端使用这个入口地址判断哪个RegionServer托管待查找的region,此过程就像一个3层分布式B+树。-ROOT-表是B+树的-ROOT-节点,.META. region是-ROOT-节点的叶子,用户表的region是.META. region的叶子
下面举个例子辅助理解
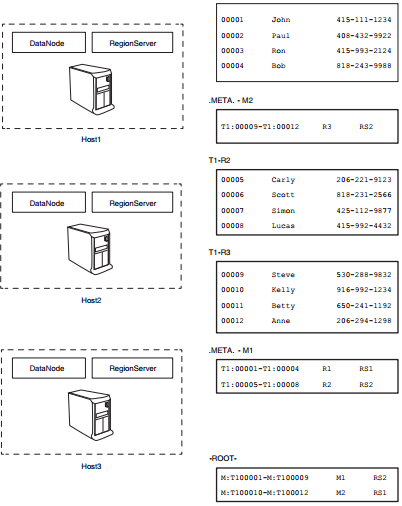
RegionServer 1(RS1)托管用户表T1的region R1和.META.表的region M2
RegionServer 2(RS2)托管用户表T1的region R2、R3和.META.表的region M1
RegionServer 3(RS3)只托管了-ROOT-
如何找到-ROOT-表
ZooKeeper提供了hbase的入口点,这些步骤如下:
step1:
客户端–>ZooKeeper:询问-ROOT-在哪里
step2:
ZooKeeper–>客户端:在RegionServer RS1上面
step3:
客户端–>RS1上的-ROOT-表:哪一个.META. region可以帮我找到表T1中的行00009?
step4:
RS1上的-ROOT-表–>客户端:在RegionServer RS3上的.META. region M2可以找到
step5:
客户端–>RegionServer RS3上的.META. region M2:我要读取表T1中的行00009,在哪个region上可以找到?哪一个RegionServer为它提供服务?
step6:
RegionServer RS3上的.META. region M2–>客户端:在RegionServer RS3上的region T1R3
step7:
客户端–>RegionServer RS3上的region T1R3:我要读取行00009
step8:
RegionServer RS3上的region T1R3–>客户端:ok,拿去吧

Comments