
本文主要介绍字符串匹配的Karp-Rabin算法
主要特征
1、使用hash函数
2、预处理阶段时间复杂度O(m),常量空间
3、查找阶段时间复杂度O(mn)
4、期望运行时间:O(n+m)
算法描述
在大多数实际情况下,Hash法提供了避免二次方比较时间的一种简单的方法. 不同于检查文本中的每一个位置是否匹配,只检查模式串和指定文本窗口的相似性似乎更高效. hash函数被用来检查两个字符串的相似度.
- 有利于字符串匹配的hash函数应该有如下的性能:
-
1. 高效可计算; -
2. 对字符串高度识别; -
3. hash(y[j+1 .. j+m]) 必须要很容易计算 hash(y[j .. j+m-1]) 和y[j+m]:
hash(y[j+1 .. j+m])= rehash(y[j], y[j+m], hash(y[j .. j+m-1]).
对于一个单词w 长度为m,hash(w) 定义如下:
hash(w[0 .. m-1])=(w[0]*2m-1+ w[1]*2m-2+···+ w[m-1]*20) mod q
其中q 是一个很大的数.
rehash(a,b,h)= ((h–a*2m-1)*2+b) mod q
Karp-Rabin 算法的预处理阶段由计算hash(x)构成. 在常量空间和O(m) 执行时间内完成.
在搜索阶段,使用hash(y[j .. j+m-1]) 0 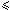 j < n–m,比较hash(x) 就足够了. 如果hash值相等,依然需要逐个字符去比较 x=y[j .. j+m-1]是否相等.
j < n–m,比较hash(x) 就足够了. 如果hash值相等,依然需要逐个字符去比较 x=y[j .. j+m-1]是否相等.
Karp-Rabin算法的搜索阶段的时间复杂度为:O(mn) (例如在an 中搜索 am).期望比较次数为: O(n+m).
举例
预处理阶段: hash[y]=17597
搜索阶段:
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[0 .. 7]) = 17819
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[1 .. 8]) = 17533
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[2 .. 9]) = 17979
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[3 .. 10]) = 19389
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[4 .. 11]) = 17339
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||||||||||||||||
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[5 .. 12]) = 17597
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[6 .. 13]) = 17102
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[7 .. 14]) = 17117
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[8 .. 15]) = 17678
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[9 .. 16]) = 17245
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[10 .. 17]) = 17917
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[11 .. 18]) = 17723
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[12 .. 19]) = 18877
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[13 .. 20]) = 19662
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[14 .. 21]) = 17885
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[15 .. 22]) = 19197
| G | C | A | T | C | G | C | A | G | A | G | A | G | T | A | T | A | C | A | G | T | A | C | G |
| G | C | A | G | A | G | A | G | ||||||||||||||||
hash(y[16 .. 23]) = 16961
上面的例子中Karp-Rabin 算法执行8个字符的比较.
C代码实现
// Completed on 2014.10.7 8:45
// Language: C99
//
// 版权所有(C)wuyudong (mail: oskernel@126.com)
// 博客地址:http://www.wuyudong.com
#define REHASH(a, b, h) ((((h) - (a)*d) << 1) + (b))
int KR(char *x, int m, char *y, int n) {
int d, hx, hy, i, j;
/* 预处理*/
/* 计算 d = 2^(m-1) 使用左移位运算操作 */
for (d = i = 1; i < m; ++i)
d = (d<<1);
for (hy = hx = i = 0; i < m; ++i) {
hx = ((hx<<1) + x[i]);
hy = ((hy<<1) + y[i]);
}
/* 搜索*/
j = 0;
while (j <= n-m) {
if (hx == hy && memcmp(x, y + j, m) == 0)
return j;
hy = REHASH(y[j], y[j + m], hy);
++j;
}
}
参考资料
- AHO, A.V., 1990, Algorithms for finding patterns in strings. in Handbook of Theoretical Computer Science, Volume A, Algorithms and complexity, J. van Leeuwen ed., Chapter 5, pp 255-300, Elsevier, Amsterdam.
- CORMEN, T.H., LEISERSON, C.E., RIVEST, R.L., 1990. Introduction to Algorithms, Chapter 34, pp 853-885, MIT Press.
- CROCHEMORE, M., HANCART, C., 1999, Pattern Matching in Strings, in Algorithms and Theory of Computation Handbook, M.J. Atallah ed., Chapter 11, pp 11-1–11-28, CRC Press Inc., Boca Raton, FL.
- GONNET, G.H., BAEZA-YATES, R.A., 1991. Handbook of Algorithms and Data Structures in Pascal and C, 2nd Edition, Chapter 7, pp. 251-288, Addison-Wesley Publishing Company.
- HANCART, C., 1993. Analyse exacte et en moyenne d’algorithmes de recherche d’un motif dans un texte, Ph. D. Thesis, University Paris 7, France.
- CROCHEMORE, M., LECROQ, T., 1996, Pattern matching and text compression algorithms, in CRC Computer Science and Engineering Handbook, A. Tucker ed., Chapter 8, pp 162-202, CRC Press Inc., Boca Raton, FL.
- KARP R.M., RABIN M.O., 1987, Efficient randomized pattern-matching algorithms. IBM J. Res. Dev. 31(2):249-260.
- SEDGEWICK, R., 1988, Algorithms, Chapter 19, pp. 277-292, Addison-Wesley Publishing Company.
- SEDGEWICK, R., 1988, Algorithms in C, Chapter 19, Addison-Wesley Publishing Company.
- STEPHEN, G.A., 1994, String Searching Algorithms, World Scientific.

Comments