
原创文章,转载请注明: 转载自工学1号馆
本文将介绍DistributedCache在Hadoop中的使用方法及实现原理。
DistributedCache是Hadoop提供的文件缓存工具,它能够自动将指定的文件分发到各个节点上,缓存到本地,供用户程序读取使用。它具有以下几个特点:缓存的文件是只读的,修改这些文件内容没有意义;用户可以调整文件可见范围(比如只能用户自己使用,所有用户都可以使用等),进而防止重复拷贝现象;按需拷贝,文件是通过HDFS作为共享数据中心分发到各节点的,且只发给任务被调度到的节点。
Hadoop DistributedCache有以下几种典型的应用场景:
1)分发字典文件,一些情况下Mapper或者Reducer需要用到一些外部字典,比如黑白名单、词表等;
2)map-side join:当多表连接时,一种场景是一个表很大,一个表很小,小到足以加载到内存中,这时可以使用DistributedCache将小表分发到各个节点上,以供Mapper加载使用;
3)自动化软件部署:有些情况下,MapReduce需依赖于特定版本的库,比如依赖于某个版本的PHP解释器,一种做法是让集群管理员把这个版本的PHP装到各个机器上,这通常比较麻烦,另一种方法是使用DistributedCache分发到各个节点上,程序运行完后,Hadoop自动将其删除。
Hadoop提供了两种DistributedCache使用方式,一种是通过API,在程序中设置文件路径,另外一种是通过命令行(-files,-archives或-libjars)参数告诉Hadoop,建议使用第二种方式,该方式可使用以下三个参数设置文件:
(1)-files:将指定的本地/hdfs文件分发到各个Task的工作目录下,不对文件进行任何处理;
(2)-archives:将指定文件分发到各个Task的工作目录下,并对名称后缀为“.jar”、“.zip”,“.tar.gz”、“.tgz”的文件自动解压,默认情况下,解压后的内容存放到工作目录下名称为解压前文件名的目录中,比如压缩包为dict.zip,则解压后内容存放到目录dict.zip中。为此,你可以给文件起个别名/软链接,比如dict.zip#dict,这样,压缩包会被解压到目录dict中。
(3)-libjars:指定待分发的jar包,Hadoop将这些jar包分发到各个节点上后,会将其自动添加到任务的CLASSPATH环境变量中。
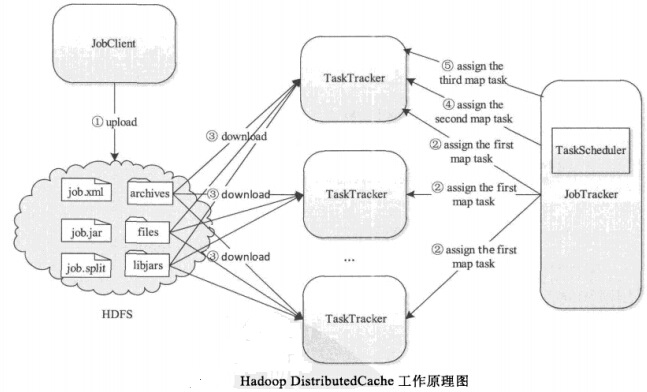
使用DistributedCache
DistributedCache第一个比较方便的作用就是来完成分布式文件共享这件事,第二个比较有用的场景,就是在执行一些join操作时,将小表放入cache中,来提高连接效率。
下面我们先通过一个表格来看下,在hadoop中,使用全局变量或全局文件共享的几种方法
| 序号 | 方法 |
| 1 | 使用Configuration的set方法,只适合数据内容比较小的场景 |
| 2 | 将共享文件放在HDFS上,每次都去读取,效率比较低 |
| 3 | 将共享文件放在DistributedCache里,在setup初始化一次后,即可多次使用,缺点是不支持修改操作,仅能读取 |
接下来将介绍,使用DistributedCache的方法,来共享一些全局配置文件或变量,通过DistributedCache的addCacheFile方法,把HDFS上的一些文件,在hadoop任务启动时,就载入缓存里面,以供全局使用,使用这个方法时,我们需要注意几点,首先我们的本地文件,需要上传到HDFS上,然后再这个方法里写入加载路径,接下来就可以在setup初始化时读取出其内容,然后在map或reduce方法执行时,就可以实时的使用这个文件的一些内容了。
测试共享的一个文件内容如下:
f1.txt,内容“wu yu dong”
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.Scanner;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//import org.apache.log4j.pattern.LogEvent;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
//import com.qin.operadb.WriteMapDB;
public class TestDistributed {
private static Logger logger=LoggerFactory.getLogger(TestDistributed.class);
private static class FileMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Path path[]=null;
/**
* Map函数前调用
*
* */
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
logger.info("开始启动setup......");
Configuration conf=context.getConfiguration();
path=DistributedCache.getLocalCacheFiles(conf);
System.out.println("获取的路径是: " + path[0].toString());
FileSystem fsopen= FileSystem.getLocal(conf);
FSDataInputStream in = fsopen.open(path[0]);
Scanner scan=new Scanner(in);
while(scan.hasNext()){
System.out.println(Thread.currentThread().getName()+"扫描的内容: "+scan.next());
}
scan.close();
}
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
System.out.println("map里输出了");
context.write(new Text(""), new IntWritable(0));
}
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException {
logger.info("清空任务了。。。。。。");
}
}
private static class FileReduce extends Reducer<Object, Object, Object, Object>{
@Override
protected void reduce(Object arg0, Iterable<Object> arg1,
Context arg2)throws IOException, InterruptedException {
System.out.println("我是reduce里面的东西");
}
}
public static void main(String[] args)throws Exception {
JobConf conf=new JobConf(TestDistributed.class);
//注意这行代码放在最前面,进行初始化,否则会报
String inputPath="hdfs://localhost:9000/user/wu/in/";
String outputPath="hdfs://localhost:9000/user/wu/out/";
Job job=new Job(conf, "a");
DistributedCache.addCacheFile(new URI("hdfs://localhost:9000/user/wu/in/f1.txt"), job.getConfiguration());
job.setJarByClass(TestDistributed.class);
System.out.println("运行模式: "+conf.get("mapred.job.tracker"));
/**设置输出表的的信息 第一个参数是job任务,第二个参数是表名,第三个参数字段项**/
FileSystem fs=FileSystem.get(job.getConfiguration());
Path pout=new Path(outputPath);
if(fs.exists(pout)){
fs.delete(pout, true);
System.out.println("存在此路径, 已经删除......");
}
/**设置Map类**/
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapperClass(FileMapper.class);
job.setReducerClass(FileReduce.class);
FileInputFormat.setInputPaths(job, new Path(inputPath)); //输入路径
FileOutputFormat.setOutputPath(job, new Path(outputPath));//输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
部分输出内容如下:
获取的路径是: /tmp/hadoop-wu/mapred/local/archive/8979102494836235044_338147689_1046069009/localhost/user/wu/in/f1.txt
Thread-2扫描的内容: wu
Thread-2扫描的内容: yu
Thread-2扫描的内容: dong
map里输出了
map里输出了
map里输出了
15/06/29 01:14:58 INFO TestDistributed: 清空任务了。。。。。。
15/06/29 01:14:58 INFO mapred.MapTask: Starting flush of map output
15/06/29 01:14:58 INFO mapred.MapTask: Finished spill 0
15/06/29 01:14:58 INFO mapred.Task: Task:attempt_local_0001_m_000001_0 is done. And is in the process of commiting
15/06/29 01:14:58 INFO mapred.JobClient: map 100% reduce 0%
15/06/29 01:15:00 INFO mapred.LocalJobRunner:
15/06/29 01:15:00 INFO mapred.Task: Task ‘attempt_local_0001_m_000001_0’ done.
15/06/29 01:15:01 INFO mapred.Task: Using ResourceCalculatorPlugin : org.apache.hadoop.util.LinuxResourceCalculatorPlugin@d9660d
15/06/29 01:15:01 INFO mapred.LocalJobRunner:
15/06/29 01:15:01 INFO mapred.Merger: Merging 2 sorted segments
15/06/29 01:15:01 INFO mapred.Merger: Down to the last merge-pass, with 2 segments left of total size: 67 bytes
15/06/29 01:15:01 INFO mapred.LocalJobRunner:
我是reduce里面的东西

Comments