
原创文章,转载请注明: 转载自工学1号馆
本文主要剖析Hadoop作业提交系列的作业文件提交过程
先看JobClient类的源代码开头的注释,翻译如下:
JobClient是一个为了将用户端作业与JobTrack连接的基础接口,JobClient提供了便利的提交作业、跟踪进度,访问组件任务的报告/日志,获取Map-Reduce集群的状态信息等等。作业提交过程涉及如下:
1、检查作业的输入输出规格
2、为作业计算InputSplits(后面的文章详细介绍)
3、如果有需要,为作业的DistributedCache计划必须的账户信息
4、将作业的jar包和配置信息复制到分布式文件系统分map-reduce的系统目录
5、向JobTrack提交作业并随时监控它的状态
通常,用户创建应用,通过JobConf类描述作业的不同方面,并使用JobClient提交作业和监控它的进度
下面是一个例子,关于如何使用JobClient:
// 创建一个新的JobConf对象
JobConf job = new JobConf(new Configuration(), MyJob.class);
// 指定不同的作业特征参数
job.setJobName("myjob");
job.setInputPath(new Path("in"));
job.setOutputPath(new Path("out"));
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
// 提交作业,调查进程知道作业完成
JobClient.runJob(job);
有时候用户可能会链接map-reduce作业用来完成那些通过单一map-reduce不能完成的复杂的任务。这相当的简单,因为job通常输出到分布式文件系统,可以将其作为另一个作业的输入。
然而,这意味着确保作业是否完成(成功/失败)的责任落在客户端,这种情况下,不同的作业控制如下:
runJob(JobConf):提交作业和返回仅仅在作业完成之后
submitJob(JobConf):仅仅提交作业,然后轮询RunningJob返回的句柄来 查询状态和做调度决定
JobConf#setJobEndNotificationURI(String):设置一个作业完成的通知,因此避免轮询
submitJob的方法源代码:
public RunningJob submitJob(JobConf job) throws FileNotFoundException,
IOException {
try {
return submitJobInternal(job);
} catch (InterruptedException ie) {
throw new IOException("interrupted", ie);
} catch (ClassNotFoundException cnfe) {
throw new IOException("class not found", cnfe);
}
}
由于该方法调用的是submitJobInternal方法,所以接下来重点分析JobClient.submitJobInternal函数:
方法源代码的前面注释:
内部的方法,作用是将作业提交到系统
@param job 提交作业的配置参数
@return 为运行的作业返回一个动态代理对象
@throws FileNotFoundException
@throws ClassNotFoundException
@throws InterruptedException
@throws IOException
完整的函数代码如下:
public
RunningJob submitJobInternal(final JobConf job
) throws FileNotFoundException,
ClassNotFoundException,
InterruptedException,
IOException {
/*
* configure the command line options correctly on the submitting dfs
*/
return ugi.doAs(new PrivilegedExceptionAction<RunningJob>() {
public RunningJob run() throws FileNotFoundException,
ClassNotFoundException,
InterruptedException,
IOException{
JobConf jobCopy = job;
Path jobStagingArea = JobSubmissionFiles.getStagingDir(JobClient.this,
jobCopy);
JobID jobId = jobSubmitClient.getNewJobId();
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
jobCopy.set("mapreduce.job.dir", submitJobDir.toString());
JobStatus status = null;
try {
populateTokenCache(jobCopy, jobCopy.getCredentials());
copyAndConfigureFiles(jobCopy, submitJobDir);
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(jobCopy.getCredentials(),
new Path [] {submitJobDir},
jobCopy);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
int reduces = jobCopy.getNumReduceTasks();
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
job.setJobSubmitHostAddress(ip.getHostAddress());
job.setJobSubmitHostName(ip.getHostName());
}
JobContext context = new JobContext(jobCopy, jobId);
jobCopy = (JobConf)context.getConfiguration();
// Check the output specification
if (reduces == 0 ? jobCopy.getUseNewMapper() :
jobCopy.getUseNewReducer()) {
org.apache.hadoop.mapreduce.OutputFormat<?,?> output =
ReflectionUtils.newInstance(context.getOutputFormatClass(),
jobCopy);
output.checkOutputSpecs(context);
} else {
jobCopy.getOutputFormat().checkOutputSpecs(fs, jobCopy);
}
// Create the splits for the job
FileSystem fs = submitJobDir.getFileSystem(jobCopy);
LOG.debug("Creating splits at " + fs.makeQualified(submitJobDir));
int maps = writeSplits(context, submitJobDir);
jobCopy.setNumMapTasks(maps);
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = jobCopy.getQueueName();
AccessControlList acl = jobSubmitClient.getQueueAdmins(queue);
jobCopy.set(QueueManager.toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getACLString());
// Write job file to JobTracker's fs
FSDataOutputStream out =
FileSystem.create(fs, submitJobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
try {
jobCopy.writeXml(out);
} finally {
out.close();
}
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, jobCopy.getCredentials());
status = jobSubmitClient.submitJob(
jobId, submitJobDir.toString(), jobCopy.getCredentials());
JobProfile prof = jobSubmitClient.getJobProfile(jobId);
if (status != null && prof != null) {
return new NetworkedJob(status, prof, jobSubmitClient);
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (fs != null && submitJobDir != null)
fs.delete(submitJobDir, true);
}
}
}
});
}
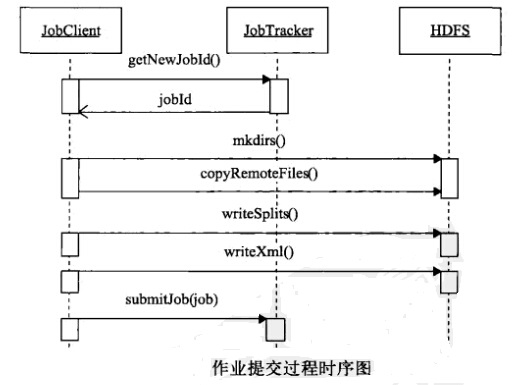
具体过程如下:
1、向jobtracker请求一个新的作业ID
JobID jobId = jobSubmitClient.getNewJobId();
2、检查作业的输出说明,如果没有指定输出目录或输出目录已经存在,作业就不提交,错误抛回给MapReduce程序
if (reduces == 0 ? jobCopy.getUseNewMapper() :
jobCopy.getUseNewReducer()) {
org.apache.hadoop.mapreduce.OutputFormat<?,?> output =
ReflectionUtils.newInstance(context.getOutputFormatClass(),
jobCopy);
output.checkOutputSpecs(context);
} else {
jobCopy.getOutputFormat().checkOutputSpecs(fs, jobCopy);
}
3、计算作业的分片,如果分片无法计算,比如因为作业路径不存在,作业就不提交,,错误抛回给MapReduce程序
FileSystem fs = submitJobDir.getFileSystem(jobCopy);
LOG.debug("Creating splits at " + fs.makeQualified(submitJobDir));
int maps = writeSplits(context, submitJobDir);
jobCopy.setNumMapTasks(maps);
4、将运行作业所需的资源复制到一个以作业ID命名的目录下jobtrackr的文件系统中,作业JAR的副本较多,因此在运行作业的任务时,集群中有很多个副本可供tasktracker访问
FSDataOutputStream out =
FileSystem.create(fs, submitJobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
try {
jobCopy.writeXml(out);
} finally {
out.close();
}
5、告知jobtracker,作业准备执行
printTokens(jobId, jobCopy.getCredentials());
status = jobSubmitClient.submitJob(
jobId, submitJobDir.toString(), jobCopy.getCredentials());
JobProfile prof = jobSubmitClient.getJobProfile(jobId);
if (status != null && prof != null) {
return new NetworkedJob(status, prof, jobSubmitClient);
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (fs != null && submitJobDir != null)
fs.delete(submitJobDir, true);
}
}

Comments