
原创文章,转载请注明: 转载自工学1号馆
有一批电话通信清单,保存了主叫和被叫的记录,记录格式下,主叫和被叫之间是以空格隔开的。
13583746322 10086
13202930239 120
13434300000 13800138000
13583746322 13800138000
13687653322 110
13777777322 10086
13583234324 10000
13583746322 13800138000
13234328847 10086
13583000000 10000
13000039984 10000
13580006322 10086
13583216322 110
现在需要做一个倒排索引,记录拨打给被叫的所有主叫号码,记录的格式如下,主叫号码之间以|分隔。
10000 13583234324|13000039984|13583000000|
10086 13583746322|13777777322|13234328847|13580006322|
110 13583216322|13687653322|
120 13202930239|
13800138000 13583746322|13434300000|13583746322|
算法思路
源文件—>Mapper(分隔原始数据,以被叫作为key,以主叫作为value)—>Reducer(把拥有相同被叫的主叫号码用|分隔汇总)—>输出到HDFS
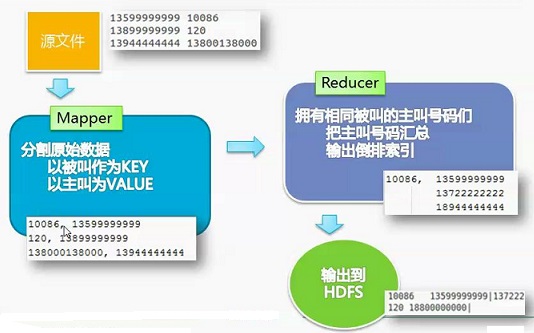
源代码如下:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class invertedindex extends Configured implements Tool{
enum Counter{
LINESKIP,//记录出错的行
}
/**
*Mapper<LongWritable,Text,NullWritable,Text>
*LongWritable,Text 是输入数据的key和value 如:路由日志的每一行的首字符的偏移量作为key,整一行的内容作为value
*NullWritable,Text 是输出数据的key和value
*
*/
public static class Map extends Mapper<LongWritable, Text, Text, Text>{
//map(LongWritable key,Text value,Context context)
//LongWritable key,Text value,和RouterMapper类的输入数据的key、value对应
//Context 上下文环境
public void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{
String line = value.toString();
try{
String[] lineSplit = line.split(" ");//分割原始数据 \\135, 10086
String anum = lineSplit[0];
String bnum = lineSplit[1];
//输出
context.write(new Text(bnum), new Text(anum));
}catch(ArrayIndexOutOfBoundsException e) {
//对异常数据进行处理,出现异常,令计数器+1
context.getCounter(Counter.LINESKIP).increment(1);
return;
}
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text>values, Context context)throws IOException,InterruptedException{
String valueString;
String out = "";
for(Text value : values) {
valueString = value.toString();
out += valueString + "|";
}
context.write(key, new Text(out));
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = new Job(conf,"invertedindex");//指定任务名称
job.setJarByClass(invertedindex.class);//指定Class
FileInputFormat.addInputPath(job, new Path(args[0]));//输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));//输出路径
job.setMapperClass(Map.class);//调用Mapper类作为Mapper的任务代码
job.setReducerClass(Reduce.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);//指定输出的key格式,要和RouterMapper的输出数据格式一致
job.setOutputValueClass(Text.class);//指定输出的value格式,要和RouterMapper的输出数据格式一致
job.waitForCompletion(true);
return job.isSuccessful()?0:1;
}
//测试用的main方法
//main方法运行的时候需要指定输入路径和输出路径
public static void main(String[] args) throws Exception{
int res = ToolRunner.run(new Configuration(), new invertedindex(), args);
System.exit(res);
}
}

Comments